
type
status
date
slug
summary
tags
category
icon
password
原始链接
- GitHub 仓库:NousResearch/hermes-agent
- 最新 release:Hermes Agent v0.18.0,2026-07-01
为什么今天选它
今天的候选里,OpenClaw 仍然是热度最高的个人 agent 项目;GitHub API 在 2026-07-04 查到它有 381,675 stars。earendil-works/pi 也很活跃,有 67,563 stars,但《智汇AI》前几天已经多次把 Pi 和 harness 作为候选或参照写过。Hermes Agent 今天更值得单独拆开:同一时间查到它有 209,008 stars、38,100 forks,仓库在 2026-07-04 还在更新;它的最新 release 是 2026-07-01 的 v0.18.0。
我选 Hermes,不是因为它星标第二高,而是因为它把 2026 年 agent 产品的几个关键问题放到同一个系统里:长期运行、跨平台入口、技能沉淀、记忆、工具权限、子 agent、自动化任务,以及后续的自我优化计划。前几天写过的 Code as Agent Harness、Microsoft Agent Framework 和 AgentFlow 更偏框架、论文或训练方法;Hermes 是一个可以直接运行的个人 agent 产品,刚好可以看这些思想落到产品里会变成什么样。
它解决的不是“怎么接模型”,而是“agent 怎么留住经验”
普通 agent 最容易做成一次性助手:用户给任务,模型调工具,最后回一句结果。问题是下次还得重新解释上下文,工具选择也不会因为上次踩坑而变好。Hermes 把自己定位成 self-improving agent,README 里明确强调它会从经验创建技能、在使用中改进技能、主动提醒自己保存知识、搜索过去会话,并建立跨会话用户模型。
这句话里有宣传成分,但方向值得看。Hermes 的核心不是又发明一个聊天入口,而是把“经验”拆成几类可保存的对象:memory、user profile、session search、skills、context files、cron jobs、toolsets。它试图让 agent 从一次性对话,变成一个带状态的工作进程。
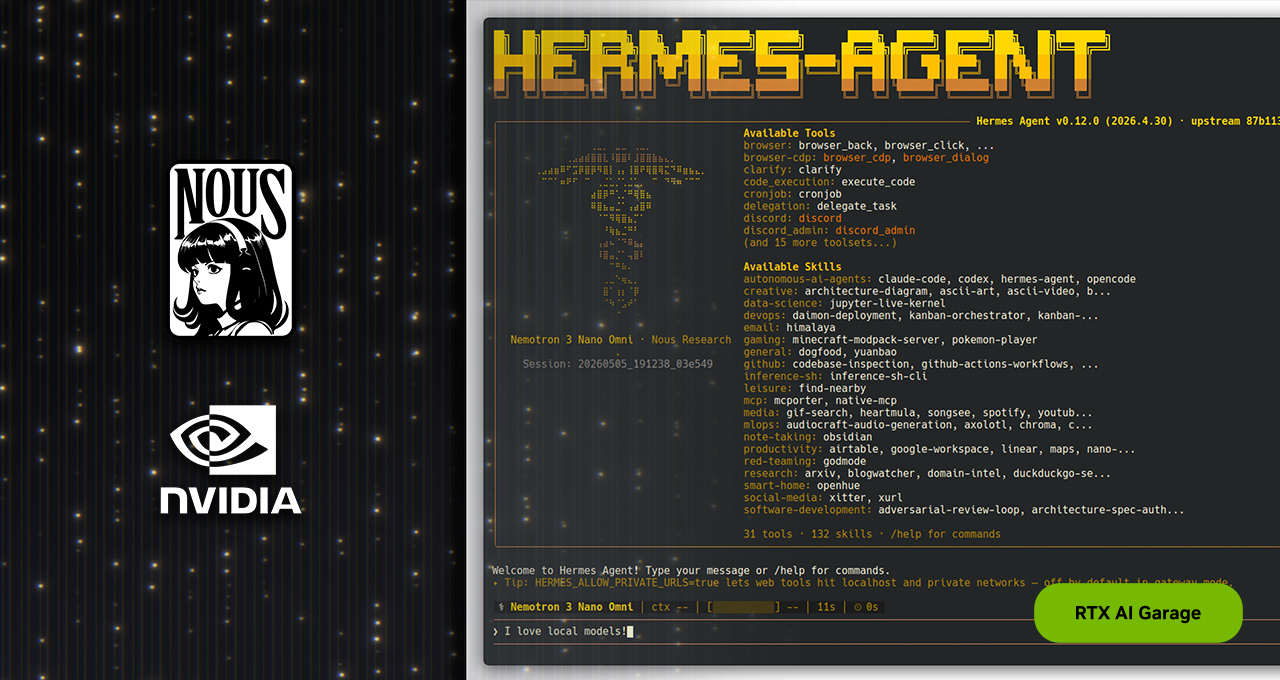
图源:NVIDIA RTX AI Garage 文章。这张图不是装饰图。右侧终端里可以看到模型、可用工具、可用技能和输入区,说明 Hermes 的产品重心放在“运行时”:模型只是其中一块,工具、技能、会话和执行环境一起构成 agent。
NVIDIA 文章称,Hermes 的四个突出点是 self-evolving skills、contained sub-agents、可靠性设计,以及“同一模型在不同框架中表现更好”的框架差异。最后一点需要谨慎看,因为文章没有给独立评测细节;但前两点确实和 Hermes 文档能对上。
系统怎么跑:一个核心 agent,多个入口
官方 Architecture 文档把入口列成 CLI、Gateway、ACP、Batch Runner、API Server 和 Python Library。它们最后都会落到
AIAgent 这个核心循环上。这个循环负责拼系统提示词、选择 provider、调用模型、执行工具、处理重试和 fallback、维护历史、压缩上下文、刷新持久记忆。Agent Loop 文档给出的单轮流程很清楚:用户消息进入历史,系统构建或复用 prompt,超过上下文阈值时先压缩,再调用模型。如果模型返回工具调用,就执行工具、把结果写回历史,再回到模型;如果返回文本,就保存 session,并在需要时刷新 memory。
这就是常见的 agent loop,但 Hermes 在几个地方做得更像产品:工具可以并发执行;用户可以中断 API 调用或工具执行;每个 agent 有 iteration budget;子 agent 有独立预算;主模型失败后可以按配置 fallback;压缩时会先把 memory 写盘,避免上下文丢失。
Prompt、memory 和 skills 被分成不同层
Hermes 的 Prompt Assembly 文档值得单独看。它把系统提示词拆成三层:stable、context、volatile。stable 里放身份、工具指导、skills index、环境提示;context 里放项目规则,比如
.hermes.md、AGENTS.md、CLAUDE.md;volatile 里放 memory snapshot、user profile、外部 memory provider、时间戳和 session 信息。这个设计的目的很实际:尽量保持前缀稳定,方便 prompt caching;同时又能让 memory 和用户资料进入每个新 session。它还把临时覆盖信息放在 API-call-time-only 层,不写进持久 prompt,避免一次性上下文污染后续对话。
Persistent Memory 文档里有一个细节:memory 写入会立刻落盘,但当前 session 的系统提示词不会在中途自动变化。新的 memory 要到下一个 session 或 prompt rebuild 路径里才会进入模型看到的快照。这不是缺陷,而是性能和语义之间的取舍。好处是缓存稳定,坏处是当前对话里刚写入的长期记忆不一定马上改变模型行为。
Skills 是它最值得拆的部分
很多 agent 项目都有“技能”概念,但 Hermes 把 skills 做成一等对象。Skills 文档说,skill 是按需加载的知识文档,使用 progressive disclosure:先只给 agent 一个技能列表,需要时再加载完整
SKILL.md,必要时再读具体参考文件。这样比把所有流程塞进系统 prompt 更省上下文,也更容易审计。更关键的是
/learn。它可以把本地 SDK、在线文档、刚刚走过的一段流程、或用户粘贴的操作说明,整理成符合标准的 SKILL.md。文档也写明,/learn 没有单独的摄取引擎,它只是把任务交给活 agent,让 agent 用现有工具收集材料,再用 skill_manage 保存结果;如果写入审批开启,就会经过 approval gate。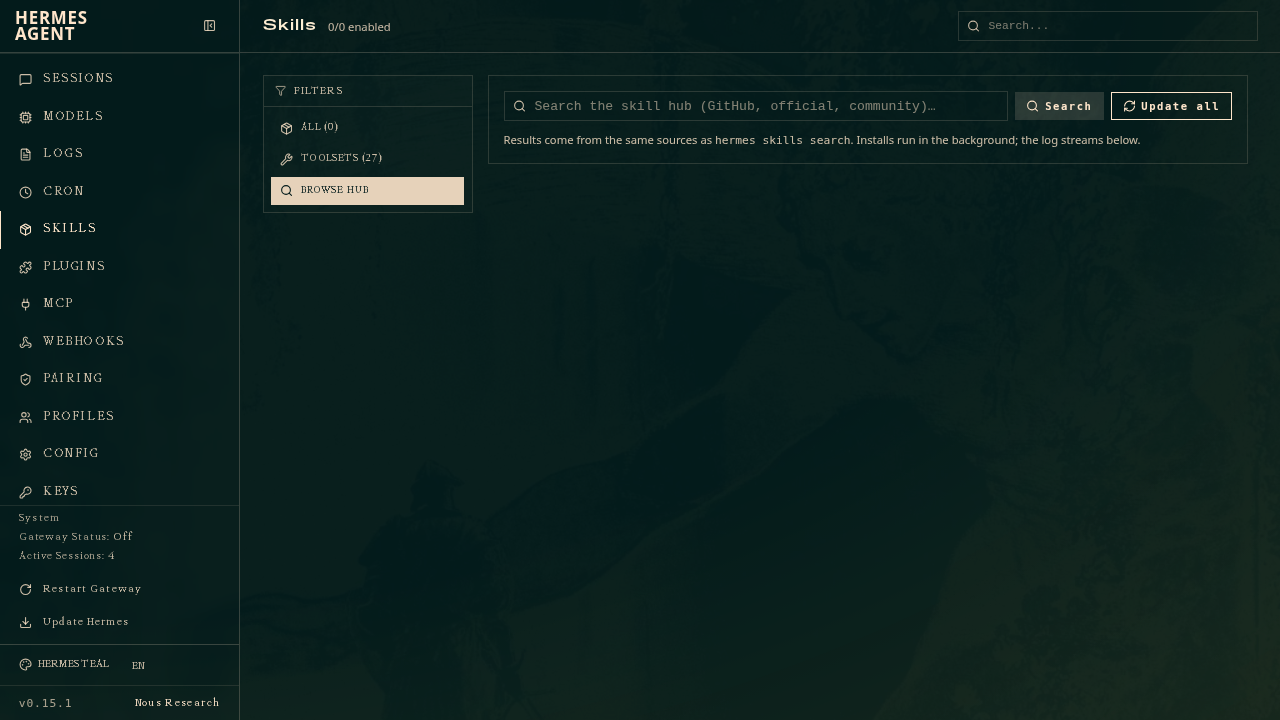
图源:Hermes Agent 仓库 dashboard 图片。这张图能看到 Skills 是可搜索、可安装、可启用的管理对象。换句话说,Hermes 没有把 skill 当成一句“下次记得这么做”的提示,而是把它做成了可管理的程序化记忆。
这也是 Hermes 真正有意思的地方:memory 保存事实,skill 保存做法。事实会过期,做法也会过期,但两者的治理方式不一样。一个好的 agent 不应该只记得“用户偏好短回答”,还应该记得“上次如何部署这个项目”“怎样审查这个仓库的 PR”“遇到某类报错先查哪几个文件”。这些更接近 procedural memory。
工具系统很宽,但宽不是重点
Tools 文档列了 web search、browser automation、terminal、file editing、memory、delegation、scheduled tasks、Home Assistant、MCP 等能力。Architecture 文档还写到,工具注册中心有 70+ tools、约 28 个 toolsets;terminal backend 包括 local、Docker、SSH、Singularity、Modal 和 Daytona。
这听起来很强,但我不认为“工具多”是 Hermes 的护城河。工具越多,误调用、权限过宽、结果污染和上下文膨胀就越严重。Hermes 真正重要的是把工具放进几个边界里:toolsets 可以按平台启用或禁用;危险命令会走 approval;MCP 是动态集成;terminal backend 可以换成本地、容器或远程环境;子 agent 可以被隔离成短任务 worker。
这比简单说“agent 能操作电脑”要具体。一个长期运行的 agent,最怕的不是不会执行,而是能执行太多却没人知道它做了什么。
Session 和 gateway 让它更像常驻进程
Hermes 支持 CLI,也支持 Telegram、Discord、Slack、WhatsApp、Signal、Email 等入口。README 里说这些入口都通过同一个 gateway process 处理。Architecture 文档把 gateway 描述为长运行进程,负责平台适配、session routing、用户授权、slash command、hook、cron ticking 和后台维护。
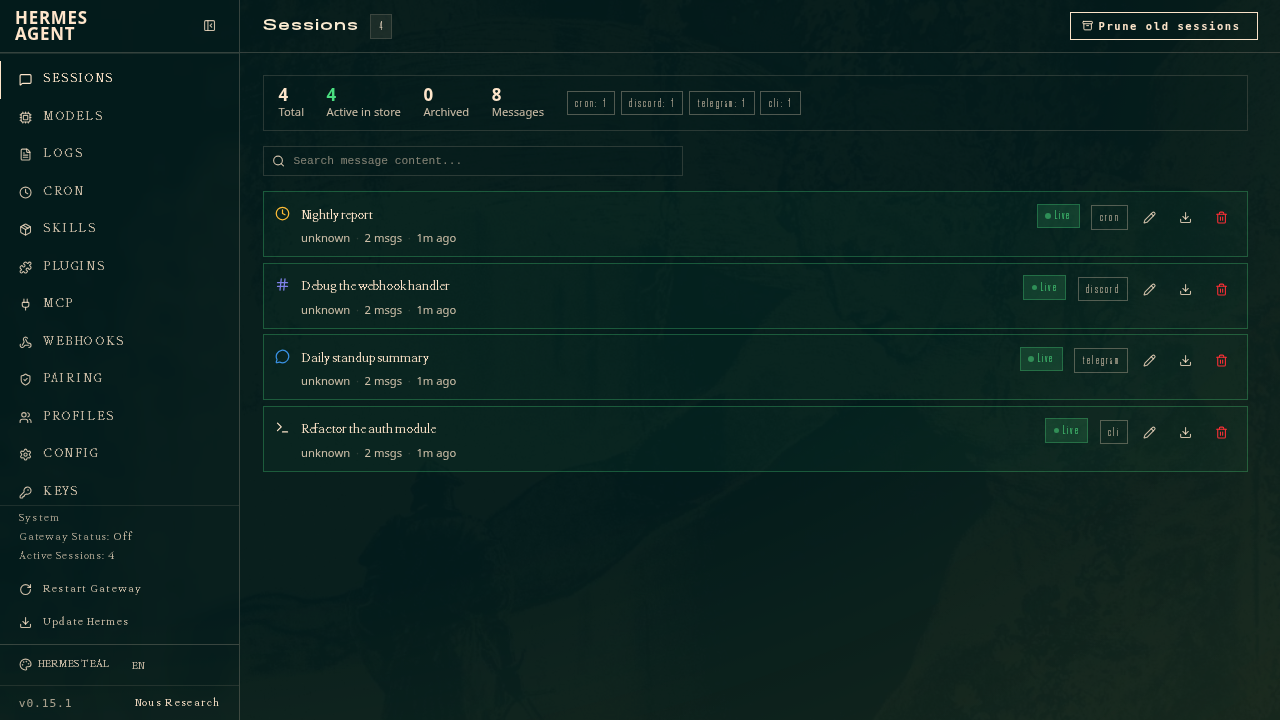
图源:Hermes Agent 仓库 dashboard 图片。这张图里能看到不同来源的 session:cron、discord、telegram、cli。这里的重点不是界面,而是状态模型。Hermes 把不同入口都变成可恢复、可搜索、可归档的会话,而不是让每个平台各自散落一份上下文。
Session Storage 文档还提到 SQLite + FTS5、session lineage、跨压缩的父子关系、平台隔离、原子写入。FTS5 让 session search 成为 recall 工具,不必只靠 memory 文件。这个区分很重要:memory 保存少量长期事实,session search 查找过去的完整经历。两者混在一起,memory 会很快变成垃圾堆。
安全机制够明确,但不是万能
Security 文档里有三种 approval 模式:manual、smart、off。默认 manual 会对危险命令询问用户;smart 会用辅助 LLM 判断风险;off 等于关闭审批。YOLO 模式可以跳过危险命令提示,但还有 hardline blocklist,像
rm -rf /、fork bomb、直接写块设备、根目录下 pipe 远程脚本到 shell 这类操作会被无条件拒绝。这个设计比很多个人 agent 更诚实:它承认 agent 会执行危险动作,也承认用户会为了方便打开 YOLO。问题是,业务场景里的危险不一定长得像
rm -rf /。给客户发错邮件、把内部文件传到外部服务、在错误环境里跑迁移、读到不该读的目录,这些都需要产品自己定义权限边界。Hermes 给了框架,但不会替团队决定哪些动作永远不能自动执行。Self-evolution:方向强,但还不能当成已完成能力
Hermes 旁边还有一个 hermes-agent-self-evolution 仓库。它的 PLAN 写得很清楚:这是独立优化管线,作用在 Hermes Agent 上,不是 Hermes Agent 本体的一部分。计划用 DSPy + GEPA、MIPROv2 和外部 code evolution 方法来优化 skills、tool descriptions、system prompt components 和部分代码。
这里最值得看的不是“自动进化”这几个字,而是它把风险顺序排得比较合理:先优化 skill files,因为它们是纯文本、容易比较、风险最低;再优化 tool descriptions;再碰 system prompt;最后才碰代码。每一步都要做 evaluation、benchmark gate、diff、PR 和 human review。
这说明 Nous 团队知道 self-improvement 最危险的地方:不是 agent 会不会自己改,而是改完怎么证明更好。没有 holdout、没有回归测试、没有人审和 rollback,自我优化只是把坏习惯写得更牢。
新在哪里,哪些只是工程包装
Hermes 的新意不在 CLI、messaging gateway、provider 切换、工具注册、dashboard 或 cron。这些都是成熟工程件,单独看没什么神秘。
它真正值得研究的是三件事。第一,把 skills 当成 procedural memory,而不是 prompt 片段。第二,把 memory、session search、context files 和 skills 分开治理,避免长期上下文变成一锅粥。第三,把自我改进放到“技能 -> 工具描述 -> prompt -> 代码”的渐进路线里,并把评测和人审放在中间。
和 OpenClaw 这类个人助理相比,Hermes 更强调“经验如何沉淀”。和 Microsoft Agent Framework 相比,Hermes 更像面向个人和小团队的常驻 agent 产品,而不是企业 SDK。和 AgentFlow 相比,它不是训练论文,而是在产品层面实现可学习的操作单元。它的价值不是证明某个算法最好,而是展示一个 agent 产品怎样把 loop、skills、memory、tools、approval 和 session 管理放在一起。
可复用的方法论
产品团队可以直接拿走几条做法。
先把知识分层:事实放 memory,用户偏好放 profile,完整经历放 session search,操作流程放 skills,项目规则放 context files。不要指望一个向量库解决所有上下文问题。
把 skill 当成要维护的产品资产。每个 skill 应该有触发条件、操作步骤、坑点、验证方式和必要资源。它应该能被搜索、安装、禁用、更新和审计。
工具权限按场景开,不按能力开。CLI、Telegram、cron、子 agent 不应该默认拥有同一套工具。越是后台自动化,越要收紧写文件、发消息、读隐私数据和调用外部系统的权限。
自我改进必须经过评测。让 agent 总结经验可以,但写进 skill 之前要有验证;改 tool description 之前要看工具选择准确率;改 prompt 之前要跑回归任务。
状态要可恢复,也要可删除。Hermes 的 session、memory、profile、skills 都是状态。长期运行的 agent 如果只有“记住”,没有“清理、替换、过期、回滚”,迟早会被自己的历史拖慢。
风险和还没验证的问题
第一,项目变化太快。GitHub API 在 2026-07-04 查到 Hermes 有 25,647 个 open issues/PRs 计数,release 页面也显示 v0.18.0 距 v0.17.0 只有十几天,却合入了大量变更。高活跃是好事,也意味着接口和行为还在变。
第二,skill 学习可能固化错误经验。用户带 agent 走过一次流程,不代表那就是最好的流程。
/learn 很方便,但如果没有验证和复盘,它会把偶然成功写成长期规则。第三,memory 的隐私和陈旧问题很难。Hermes 把 memory 和 user profile 做了容量限制,也把 session search 分开,但这只能降低噪音。真实使用里,用户偏好会变,项目状态会变,跨平台身份也可能混乱。
第四,审批机制覆盖的是一部分风险。命令危险可以用 blocklist 和 approval 兜底,业务风险更难靠正则识别。企业使用前还要做数据边界、网络边界、凭证边界和审计。
第五,self-evolution 还处在路线图和配套仓库阶段。它的方向很好,但不能把它当成已经证明 Hermes 会稳定自我进化。现在更准确的说法是:Hermes 已经有经验沉淀机制,团队正在把这些机制推向可评测的优化管线。
今日沉淀
- memory 记事实,skills 记做法,session search 找经历。
- agent 真正的学习,不是多存聊天记录,而是把成功流程变成可验证技能。
- 工具越多越要分平台、分权限、分审批。
- 自我优化必须先从低风险文本资产开始,别一上来让 agent 改核心代码。
- 长期运行的 agent,最重要的是状态治理,不是单轮回答质量。
- 作者:智汇AI
- 链接:http://easyai.fyi/article/hermes-agent-deep-analysis-2026-07-04
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。